Incorporated code excerpts from the Gradio Interface Documentation and the file webui.py [Line 122] in the repository https://github.com/lllyasviel/Fooocus. While I played a central role in its creation, the code received a cursory review. Additional assistance was provided by ChatGPT. Implemented the capability to pass --share, --port, and --listen arguments to the gradio.Interface.launch() function, cascading down to the gradio app module located at /facefusion/uis/core.py. Enhanced the headless option with the functionality to prompt users for any absent paths. This guards against initiating the app in headless mode without path specification, fostering a learning environment that embraces errors. This addition accommodates diverse user behaviors. Revised help texts in /facefusion/wording.py accordingly. Established novel global variables for housing file paths. NOTE: Shaped the writing tone of the extended description under the guidance of ChatGPT, deriving from a description initially crafted by a human. See respective Pull Request for initial human description. |
||
|---|---|---|
| .github | ||
| facefusion | ||
| tests | ||
| .editorconfig | ||
| .flake8 | ||
| .gitignore | ||
| mypy.ini | ||
| README.md | ||
| requirements-ci.txt | ||
| requirements.txt | ||
| run.py | ||
FaceFusion
Next generation face swapper and enhancer.

Preview
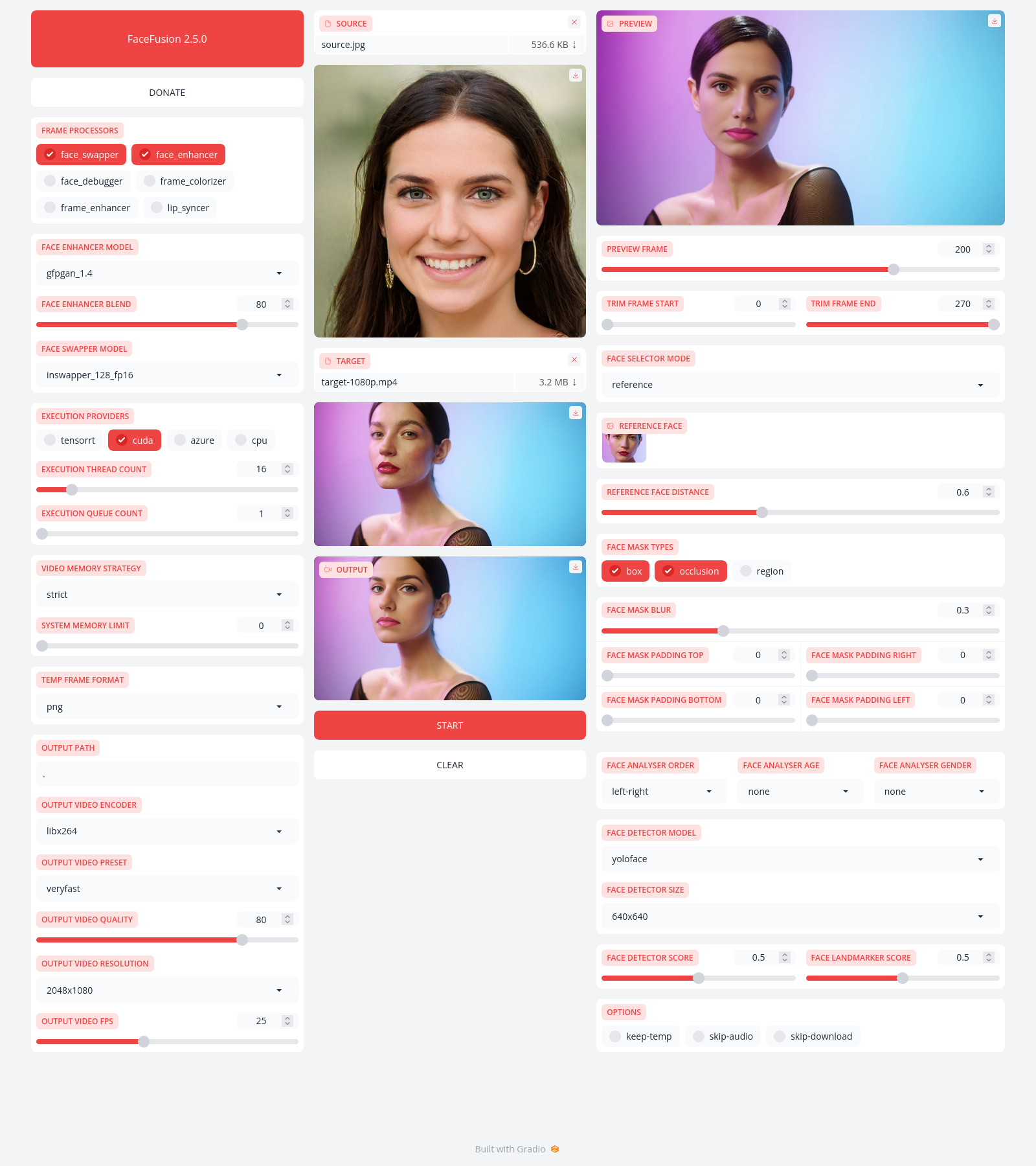
Installation
Be aware, the installation needs technical skills and is not for beginners. Please do not open platform and installation related issues on GitHub. We have a very helpful Discord community that will guide you to install FaceFusion.
Basic - It is more likely to work on your computer, but will be quite slow
Acceleration - Unleash the full potential of your CPU and GPU
Usage
Start the program with arguments:
python run.py [options]
-h, --help show this help message and exit
-s SOURCE_PATH, --source SOURCE_PATH select a source image
-t TARGET_PATH, --target TARGET_PATH select a target image or video
-o OUTPUT_PATH, --output OUTPUT_PATH specify the output file or directory
--frame-processors FRAME_PROCESSORS [FRAME_PROCESSORS ...] choose from the available frame processors (choices: face_enhancer, face_swapper, frame_enhancer, ...)
--ui-layouts UI_LAYOUTS [UI_LAYOUTS ...] choose from the available ui layouts (choices: benchmark, default, ...)
--keep-fps preserve the frames per second (fps) of the target
--keep-temp retain temporary frames after processing
--skip-audio omit audio from the target
--face-recognition {reference,many} specify the method for face recognition
--face-analyser-direction {left-right,right-left,top-bottom,bottom-top,small-large,large-small} specify the direction used for face analysis
--face-analyser-age {child,teen,adult,senior} specify the age used for face analysis
--face-analyser-gender {male,female} specify the gender used for face analysis
--reference-face-position REFERENCE_FACE_POSITION specify the position of the reference face
--reference-face-distance REFERENCE_FACE_DISTANCE specify the distance between the reference face and the target face
--reference-frame-number REFERENCE_FRAME_NUMBER specify the number of the reference frame
--trim-frame-start TRIM_FRAME_START specify the start frame for extraction
--trim-frame-end TRIM_FRAME_END specify the end frame for extraction
--temp-frame-format {jpg,png} specify the image format used for frame extraction
--temp-frame-quality [0-100] specify the image quality used for frame extraction
--output-video-encoder {libx264,libx265,libvpx-vp9,h264_nvenc,hevc_nvenc} specify the encoder used for the output video
--output-video-quality [0-100] specify the quality used for the output video
--max-memory MAX_MEMORY specify the maximum amount of ram to be used (in gb)
--execution-providers {cpu} [{cpu} ...] choose from the available execution providers (choices: cpu, ...)
--execution-thread-count EXECUTION_THREAD_COUNT specify the number of execution threads
--execution-queue-count EXECUTION_QUEUE_COUNT specify the number of execution queries
-v, --version show program's version number and exit
--share set whether to share on Gradio
--port set the listen port
--listen set the listen interface
Using the -s/--source, -t/--target and -o/--output arguments will run the program in headless mode.
Disclaimer
This software is meant to be a productive contribution to the rapidly growing AI-generated media industry. It will help artists with tasks such as animating a custom character or using the character as a model for clothing etc.
The developers of this software are aware of its possible unethical applications and are committed to take preventative measures against them. It has a built-in check which prevents the program from working on inappropriate media including but not limited to nudity, graphic content, sensitive material such as war footage etc. We will continue to develop this project in the positive direction while adhering to law and ethics. This project may be shut down or include watermarks on the output if requested by law.
Users of this software are expected to use this software responsibly while abiding the local law. If face of a real person is being used, users are suggested to get consent from the concerned person and clearly mention that it is a deepfake when posting content online. Developers of this software will not be responsible for actions of end-users.
Documentation
Read the documentation for a deep dive.